Extraction de METAdonnées par REconnaissance VocalE
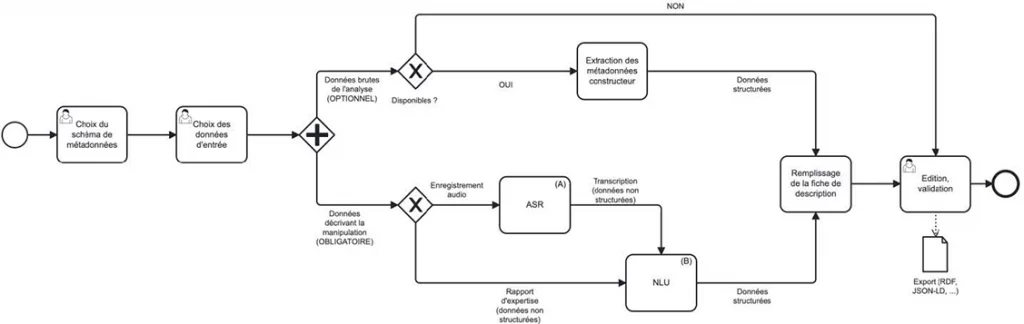
Pour les sciences du patrimoine, terrain de production de savoirs sociétaux et collectifs reposant sur une perpétuelle confrontation entre objets matériels et études pluridisciplinaires alliant sciences humaines et sociales et sciences expérimentales, les enjeux de gestion de données numériques se trouvent aujourd’hui, grâce à l’acquisition d’une maturité récente, confrontées à la forte hétérogénéité de sources documentaires (textes, images, vidéos, …), de données analytiques (issues de divers capteurs, techniques d’imagerie, analyses d’échantillons, …) et de processus de traitement mobilisés à des fins de description, analyse, suivi, ou encore conservation. Garantes de la fiabilité d’une donnée, les métadonnées et paradonnées de provenance fournissent des renseignements précieux pour rendre compte des contextes d’acquisition et des possibilités de réutilisation ultérieures. Cependant, leur production rigoureuse se révèle bien souvent chronophage voire fastidieuse, les informations à renseigner étant à la fois diverses et difficiles à retrouver a posteriori. Dans ce contexte, le projet interdisciplinaire METAREVE propose de simplifier cette démarche en l’accompagnant depuis la production des données sur le terrain jusqu’à leur traitement ex situ. La méthode innovante proposée vise à automatiser l’extraction de ces informations à l’aide d’approches de compréhension automatique de la parole empruntées au domaine de l’intelligence artificielle, en s’appuyant pour cela sur des thésaurus construits par les différentes communautés mobilisées dans les sciences du patrimoine. Il a en particulier pour objectif de fournir une brique logicielle qui pourra alimenter l’écosystème développé dans le cadre de l’EquipEx+ ESPADON.
Contact : Violette Abergel
Membres du MAP : Violette Abergel
Partenaires du projet : Vincent Detalle (SATIE), Olivier Malavergne (CRC), Besma Zeddini (SATIE)
Financement : 2023-2024 (Fondation des Sciences du Patrimoine)
Publications associées au projet :
[1] Ministère de la Culture et de la Communication – Secrétariat général, « Métadonnées culturelles et transition Web 3.0. », Ministère de la Culture et de la Communication, Paris, France, Feuille de route stratégique 2014‑01, 2014.
[2] M. D. Wilkinson et al., « The FAIR Guiding Principles for scientific data management and stewardship », Sci Data, vol. 3, no 1, p. 160018, 2016, doi: 10.1038/sdata.2016.18.
[3] B. Mons, et al., « Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud », ISU, vol. 37, no 1, p. 49‑56, 2017, doi: 10.3233/ISU-170824.
[4] L. Castelli, et al., « Heritage Science and Cultural Heritage: standards and tools for establishing cross-domain data interoperability », Int J Digit Libr, vol. 22, no 3, p. 279‑287, sept. 2021, doi: 10.1007/s00799-019-00275-2.
[5] D. Myers, et al., « The Arches heritage inventory and management system: a platform for the heritage field », Journal of Cultural Heritage Management and Sustainable Development, vol. 6, no 2, p. 213‑224, 2016, doi: 10.1108/JCHMSD-02-2016-0010.
[6] S. Tournon, et al., « Comment gérer les projets 3D collaboratifs en SHS? », in Humanistica 2020, Bordeaux, France, mai 2020, 11p.
[7] J. Li, et al., « A survey on deep learning for named entity recognition », IEEE Transactions on Knowledge and Data Engineering, vol. 34, no 1, p. 50‑70, 2020.
[8] S. Van Hooland, et al., « Named-entity recognition: a gateway drug for cultural heritage collections to the linked data cloud ? », Literary and Linguistic Computing, vol. 1, 2013.
[9] S. Van Hooland, et al., « Exploring entity recognition and disambiguation for cultural heritage collections », Digital Scholarship in the Humanities, vol. 30, no 2, p. 262‑279, 2015, doi: 10.1093/llc/fqt067.
[10] A. Felicetti, et al., « NLP Tools for Knowledge Extraction from Italian Archaeological Free Text », in 2018 3rd Digital Heritage International Congress (DigitalHERITAGE), San Francisco, CA, USA: IEEE, 2018, p. 1‑8. doi: 10.1109/DigitalHeritage.2018.8810001.
[11] M. Ehrmann, et al., « Named Entity Recognition and Classification on Historical Documents: A Survey », 2021, doi: 10.48550/ARXIV.2109.11406.
[12] A. Bombini, et al., « A Cloud-Native Web Application for Assisted Metadata Generation and Retrieval: THESPIAN-NER », Applied Sciences, vol. 12, no 24, 2022, doi: 10.3390/app122412910.
[13] M. Malik, et al., « Automatic speech recognition: a survey », Multimedia Tools and Applications, vol. 80, p. 9411‑9457, 2021.
[14] W3C, « Web Speech API, draft community group report », 18 août 2020. https://wicg.github.io/speech-api/ (consulté le 31 mars 2023).
[15] J.-M. Vallet et al., « Development of a NDT toolbox dedicated to the conservation of wall paintings: Application to the frescoes chapel in the Charterhouse of Villeneuve-lez-Avignon (France) », in 2013 Digital Heritage International Congress (DigitalHeritage), Marseille, France: IEEE, 2013, p. 67‑74. doi: 10.1109/DigitalHeritage.2013.6744731.